
A wave of “deep research” released beyond AI Labs recently. Google reveals its deep research on Dec. 2024, the Opasii followed the deep research of February 2025, and the confusion introduces deep research. Meanwhile, Deepsheek, Qwen’s Qwen’s Qwen’s qwen musk beside it, many open-sour-source implementations implemented the deep research of GitHub. It seems that deep research is to take the acquisition of taking 2025 – Everything is rebranded and sold as “deep research” without reality.
Is it familiar? It reveals the hype around the rug of 2023, agents, and agentic rags in months past. To cut clutter, this blog post checks different flavors of “deep research” from a viewpoint of technical implementation.
“” The deep research uses AI to explore complex topics for you and give you the findings of complete, easy to go back to complex tasks to save you in time. “- Google“
“Deep Research is Openai’s next agent that can do work for you independently-you give it a prompt, and chatgpt will find, analyze, and synthesize hundreds of online sources to create a comprehensive report at the level of a comprehensive report.” – Openi
“” If you ask for a deep question of research, the confusion does dozen searches, read hundreds of sources, and reasons by reporting material. “- confusion“
Marketing Jargon is referred to, here is the brief definition of deep research:
“Deep research is a generation system that takes a user question, using multiple language models (LLMS) agents searching for and analyzing information as this output.”
Of natural language processing (NLP) terms, it is known to be report generation.
Report generation – or deep research – a focus of AI engineering since the debuting chatgtt. I personally experimented with it during the Hactathhon in the early 2023, a time when AI engineering was gone. Tools such as Langchain, AutoGPT, GPT-Rociewercher, and prompt engineering, along with countless twitter demos and LinkedIn, gained significant attention. However, the real challenge is in the implementation details. Below, let us examine common guidelines for building construction generation systems, highlight their differences, and classify sacrifices from different vendors.
Unrained: Girested Acyclic Graph (DAG)
Early on, AI is aware of engineers who ask a LLM such as GPT-3.5 to create a report from the beginning is not practical. Instead, they turned Composite patterns in the chain together with many LLM calls.
The process usually works like this:
- Decompose the user’s question – Sometimes use step prompts to prompt (Zheng et al, 2023) – To create an outline of the report.
- For each section, get relevant information from search engines or knowledge bases and submits them.
- Finally, use LLM to conform to the sections of a cohesive report.
A primary example GPP-resiecearcher.
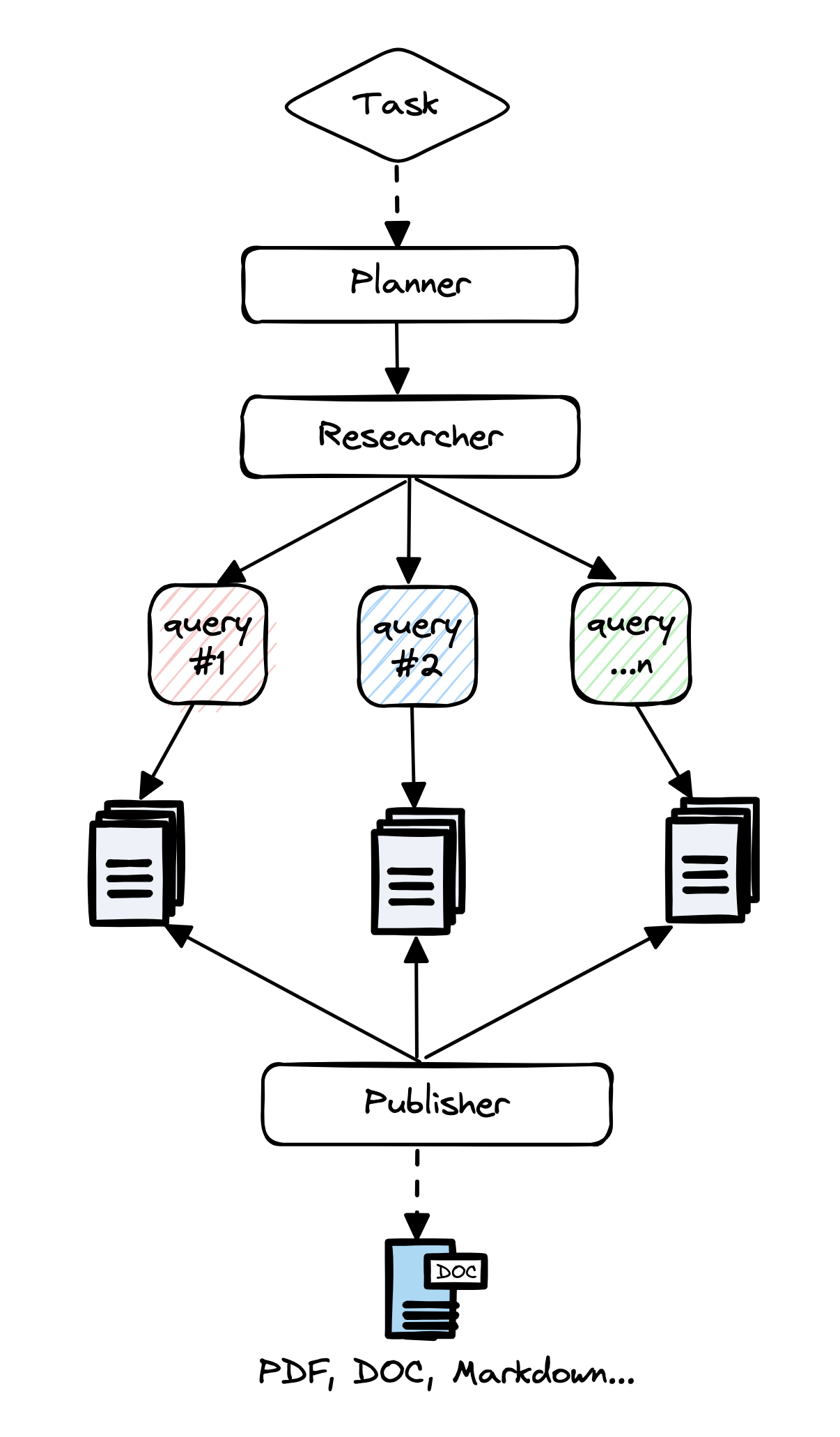
Each prompts this system per a careful hand handed by “prompt engineering.” Checking depends on the subject eyeballing of outputs, resulting in uneven quality of reporting. It’s great when it works.
To improve the quality of reporting, engineers have added the complexity of the dagger. Instead of a passing process, they indicate structural standards such as reflexion (Shinn et al, 2023) and self-reflection, where LLM reviews and self-reach output. It changes plainly in a final state machine (FSM), with parts that lead to state transitions.
This illustration from Jina.ai appeared in the way:
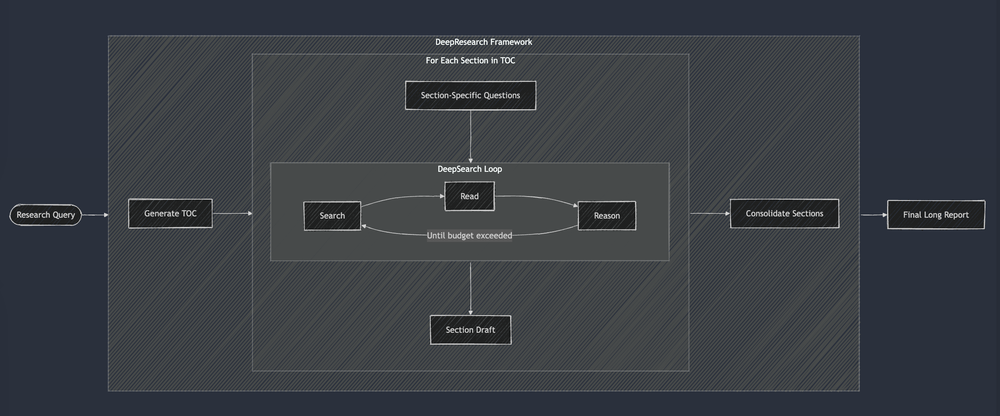
Like the method of Dag, every stimulation is handmade, and hand evaluations remain subjective. The quality of reporting continues to be different because the system is hand.
Trained: End of last
Disadvantages in the previous methods-scary engineering prompts and a lack of measurement measure – prompts a transition. Stanford’s storm (Shao et al, 2024) refers to these issues by optimizing the system at the end of the DSPY (Khattab et al, 2023).
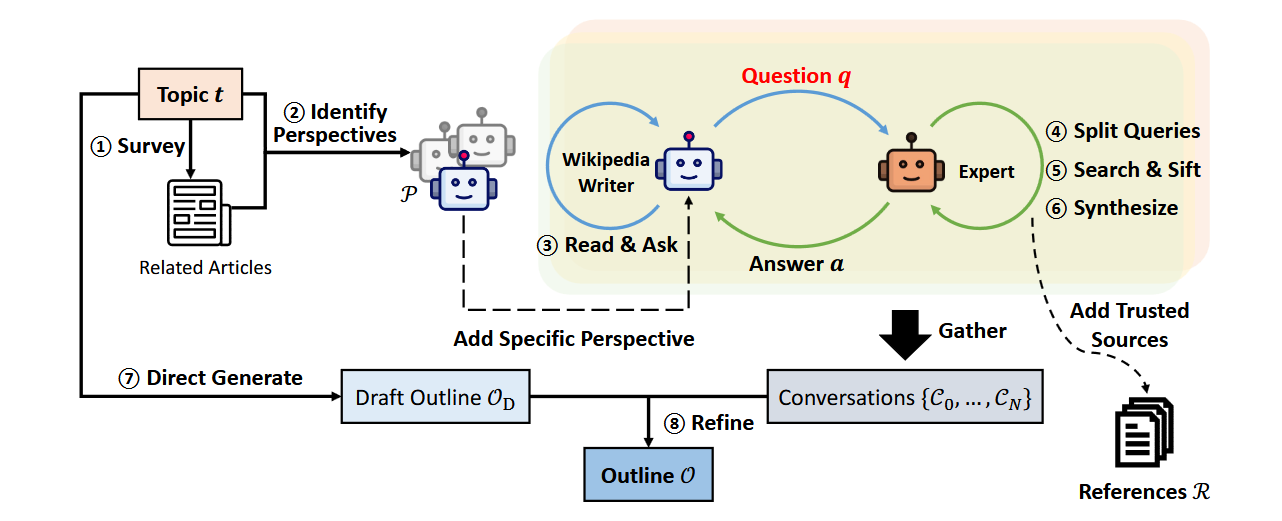
The result? The storm creates reports of waging Wikipedia articles in quality.
Trained: Many models of reason
Advances of the rational capabilities that cause many models of reasoning is an inspirational choice for deep research. For example, opuii describes how it trains in the deep research model. Note using OpenI LLM-AS-A-JUSTCE and Rubruation rubrics to grade outputs.

Google’s Gemini and Werplexity’s Chat Assistants also provide parts of “deep research, but neither prints any literature on how they are optimizing their models or a product manager. Talk to the podcast that they “have special access per se. It is more similar model (Gemini 1.5). We will of course have our own, uh, post-training work we do”. We will make a thought that what has been a good tuning work is not big. Meanwhile, the grak of Xai in the report generation, even if it is not searched beyond two iterations – several times for outlined sections, and several times per section.
We make a concept map to assess the deep research capability in different popular services. The vertical axis measures the research depth, described in how many cycles of a service a service is made to collect more information based on first-knowledge. Horizontal Axis checks the training level, from the hand-employed systems (eg, those who use manned manual learning systems. Examples of trained systems include:
OpenAI Deep Research: Optimized specifically for research tasks through reinforcement learning.
DeepSeek: Trained for general reasoning and tool use, adaptable to research needs.
Google Gemini: Instruction fine-tuned large language models (LLMs), trained broadly but not specialized for research.
Stanford STORM: A system trained to streamline the entire research process end-to-end.
This framework promotes how the balance of balance of ignoring itative research with sophisticated training, offering a clearer picture of their deepest resortion.

The deep scene of research is progressing at a speed speed. Techniques flip or unavailable six months ago can succeed today. Name conventions remain murmur, increases with confusion. Hopefully, this post explains technical discussions and cut hype.
@article{
leehanchung,
author = {Lee, Hanchung},
title = {The Differences between Deep Research, Deep Research, and Deep Research},
year = {2025},
month = {02},
howpublished = {\url{https://leehanchung.github.io}},
url = {https://leehanchung.github.io/blogs/2025/02/26/deep-research/}
}
https://leehanchung.github.io/assets/img/2025-02-26/05-quadrants.png
2025-03-03 01:59:00



