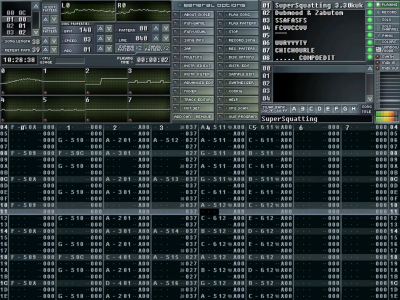

there a YouTube tune I’ve always liked called “Supersquatting.” It was written by Dubmood and Zabutom, two master chiptune composers, but this track always struck me as full and “fat.” For those who don’t know, these types of chiptunes are usually written in “tracker” software which is a category of music composing program popular in the 90s and early 2000s– they create self-contained “module” files. music tracks with both note data and samples, which can be played back immediately in a game, keygen , or just for listening. There’s a culture surrounding demoscene-related music trackers, video games, and cracking software, but I digress– here’s a nice in depth explanatory video on this if you are interested.
The point is, this track Supersquatting in particular sounds very full, more than what I usually consider possible with (nowadays) basic tools (FastTracker II), so I really believe when I first heard it should have been done in a more traditional DAW with VSTs and such. But Dubmood himself put a upload to YouTube to play the track in Skale Trackerand I see it’s just an 8 channel FastTracker II tune. Damn. Maybe the channels have some EQ on them or something, but still, that’s pretty cool for an XM file.
Unfortunately I scoured the internet and didn’t see it uploaded anywhere. It is believed that (judging by the “Razer 1911 intro edit” tagline) it must be embedded in a software crack somewhere but I can’t find any information about it, and I don’t want to go to the install a bunch of old warez to check.
One great thing about this format is that the music is, in a sense, “open source.” If you have the module, you can open it in the editor and steal the samples, mess with the notes, and generally see how it’s done. So I really want to get this tune just to listen and maybe make an arrangement myself. An idea popped into my head while about “scraping” note data from a tune like this by doing OCR on a YouTube video itself… just sitting there. When I saw this holy-grail tune uploaded to YouTube, and I was given some free time during the holidays, I thought it was time to give it a go and see how good the idea was.
Of all the classical OCR libraries out there, Tesseract is probably the most popular. There are a few knobs to tweak it, but generally you chuck your image into it and let it rip. I actually think it works pretty well, since it’s monospaced, easy-to-read characters that should theoretically be a perfect match for these old-school OCR methods. There is one Lisp bindings are there for thisso I quickly grabbed it, pointed it at a sample image, and…

Wtf? I tried all kinds of methods to process the image, adjust the text, whatever, and the Tesseract sucked every time. I’m not sure if it’s optimized for printing or what, but I can’t for the life of me get it to produce correct scans more than 50% of the time. So it seems almost worthless at this time.

Historically I’ve been really impressed with GPT-4o’s ability to transcribe images. It’s not scientific evidence or anything, but almost everything I chuck at it, even small readable text it usually gets it perfectly, so I think that this platonically ideal OCRable text, it will never fail. .. is that right?

Urghhh, slightly better than Tesseract, but still, wtf. Again I tried several methods to improve its readability, but nothing worked perfectly. It gets it right most of the time but sometimes it goes crazy and puts something completely wrong. I think that’s what you get when you have “intelligence” that interprets visual data. I also tried Gemini, same situation. In retrospect, maybe I should have lowered the temperature, but regardless, this solution is still a bit excessive, since it makes a separate HTTP request to a large GPU-based model for each small piece of text, worth a (relative) fortune , and taken forever.

ax6 on the GBDev Discord recommended that since I already know the exact shapes of the characters, and they are on a fixed grid, I can just do a pixel diff with a set of known ones form and choose the one with the lowest difference. I know it’s possible but I’d like to keep the solution somewhat generic– if you want to apply this method to a different tracker, different resolution, or anything else exactly setup here, you need to be diligent. go get the “known” character set again and find the rectangles of interest, blah blah. But since the other 2 methods didn’t work, I decided to try this one.
I booted up Skale Tracker on my system, typed in notes to see every known character, and then extracted the characters into GIMP. I wrote (well, wrote in ChatGPT) a small script to drop the clipboard into a PNG file, and then I can just hit Ctrl-C in GIMP, double click the script, type the character name, and repeat to quickly get the character images.. . which was less painful than I had planned actually .
I wrote a little code to load the directory, and a function to convert a series of “rectangles of interest” into an OCR’d string.
(defun load-dir (dir)
(loop for file in (uiop:directory-files dir)
for nsfile = (namestring file)
when (search "png" nsfile)
collect
(let ((wand (magick:new-magick-wand)))
(magick:read-image wand nsfile)
(thresh wand 0.5)
(cons wand (no-extension file)))))
(defun classify (src rect &key (x-offset 0) (y-offset 0))
(apply #'concatenate 'string
(loop for entry in rect
collect
(destructuring-bind (img-set x y w h) entry
(with-crop src crop ((+ x (* x-offset *col-offset*))
(+ y (* y-offset *row-offset*))
w
h)
(-> img-set
(symbol-value)
(alexandria:extremum #'< :key (lambda (x) (compare-images (car x) crop)))
(cdr)))))))
Cool Lisp Stuff
I included Lisp in the title so I can give you what you came for and sing its praises a bit 
To do the image management, I use lisp-magick-wand which is a thin wrapper around ImageMagick. One thing I like about Lisp is that you can easily wrap native code (even automatically) and then play around with it in the REPL. There are so many useful C/Rust/whatever libraries out there, but the traditional edit/compile/run cycle just makes iteration clunky and slow. Being able to quickly load code and start messing with it is fantastic for productivity. To make it even better, I found that SLIME has a contribution called `slime-media` that allows you to display images in the REPL. I then wrote a wrapper function:
(defun show (wand)
(let ((name (format nil "/dev/shm/~a.png" (gensym))))
(magick:write-image wand name)
(swank:eval-in-emacs `(slime-media-insert-image (create-image ,name) ,name))
wand))
and suddenly I have the ability to interactively perform operations on the image and see the result immediately!

I think you can do it with Python + Jupyter too, but I don’t know, it feels really good to me, like it’s a natural extension of the REPL experience. It also helps a lot while testing the threshold values for the image to see what works best for classification.
I wired everything up by having FFmpeg dump a series of BMP images into a pipe (so I could easily parse the buffer size and read it in lisp-magick-wand) and set up a parallelized loop to call `classify` and store the parsed-out data.
(defun drive ()
(let ((process (uiop:launch-program
'("ffmpeg" "-i" "./supersquatting-trimmed.webm"
"-f" "image2pipe" "-vcodec" "bmp" "-")
:output :stream)))
(unwind-protect
(let ((output-stream (uiop:process-info-output process)))
(run output-stream))
(uiop:close-streams process))))
From there it’s a simple matter of formatting the rows according to the OpenMPT paste format, and sending them to the clipboard.
Here is another good trick for you:
(defmacro with-output-to-clipboard (&body body)
"Captures output from body forms and sends it to xclip. Returns the captured string."
`(let ((result (with-output-to-string (output-stream)
(let ((*standard-output* output-stream))
,@body))))
(with-input-from-string (input result)
(uiop:run-program '("/usr/bin/xclip" "-in" "-sel" "clipboard")
:input input
:force-shell nil))
result))
So I can only:
(with-output-to-clipboard (print-all-orders))
and paste the result directly into OpenMPT. The crazy thing is, it actually works:
Well, it doesn’t sound much like the original module, but that’s because I lost all the original samples– I just replaced most of the square waves. There are also some “typos” from video artifacts that cause letters to be misclassified. Fortunately, my curiosity about this particular “nerd snipe” has been satisfied for now. Now that I (mostly) have the note data for this track, I’d like to make an arrangement for OPL3 and include it in game i’m doing… just need to ask Dubmood and Zabutom for permission first 
The code is everything here.
This has nothing to do with Lisp, but if you like video processing problems and want to work with me, apply at Recall.ai
2025-01-05 12:29:00



