

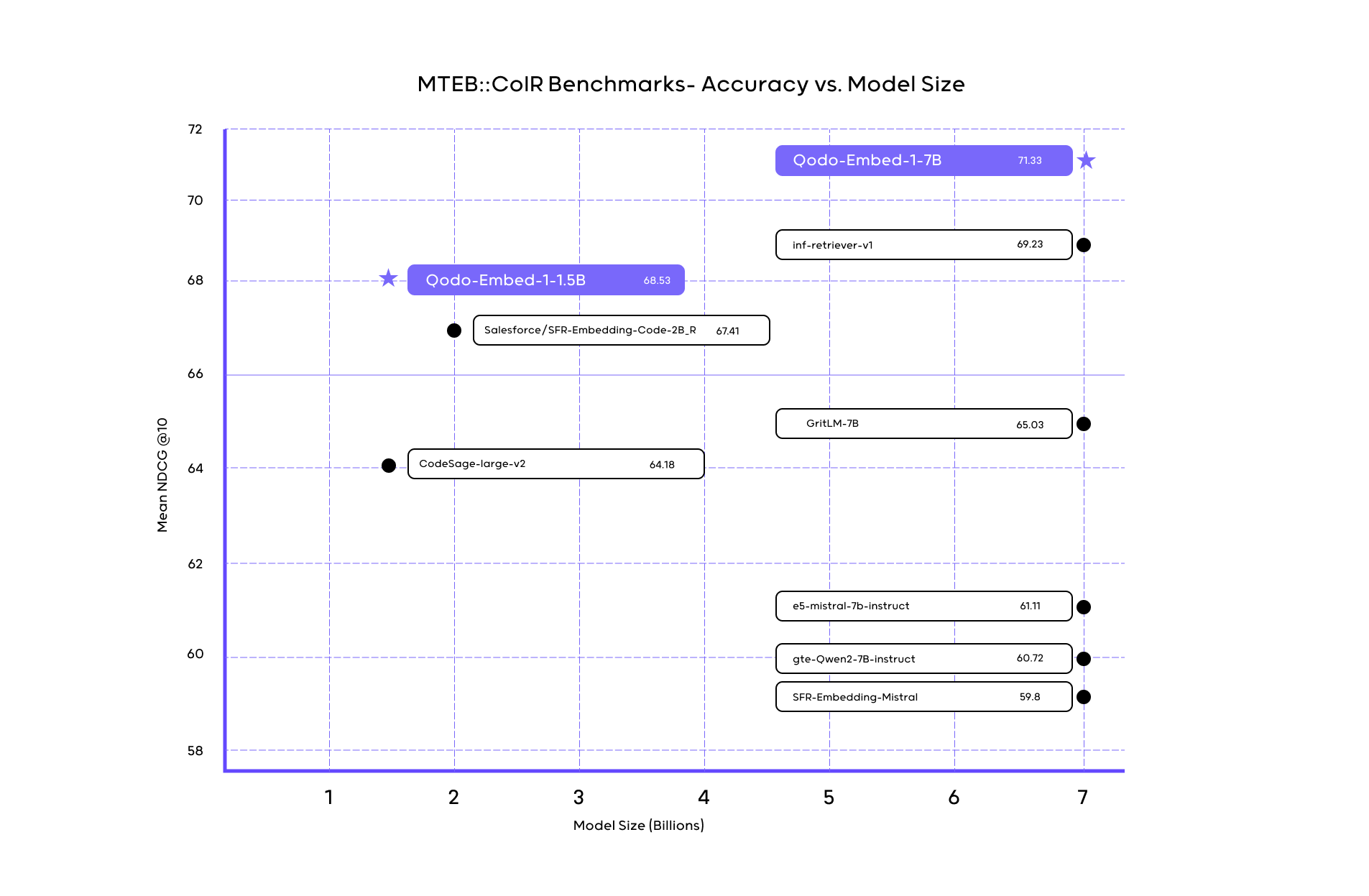
Today, we are eager to announce the QODE embed-1, a new Embedding family reached state-of-the-art on stage than a smaller step than there were models. on Coir benchmark-No the measurement of contextual capture model – Our 1.5B model scored 68.53 larger 7b models. QODO-embed-1-7b, larger QODO model, also models of the same size, scored in 71.5. On this blog, we will share our methods with Embedding models in training codes using synthetic data generation.
The challenge of the code of embedding
The main challenge of existing code embedded models is their difficulty accurate taking related codes snippet based on questionnaired language questions. Many models of generalized embedding objective such as OpenI ambulation-embedding-3-grown language standards such as codex, variable dependences, flowing. This gap has brought unrelated searches or incorrect search results and retrieving code, critical for compliance AI Coding Agents.
Here is an instance of a conventional case where models of overall embedding purposes fall:
Inquire: Make operations more reliable when they will fail sometimes
It’s fine, we hope a code snippet executing a retry or fail-safe mechanism. However, a general purpose of eventing eventding (such as OpenI embedding-3-Great) 3-Great) Return the following code:
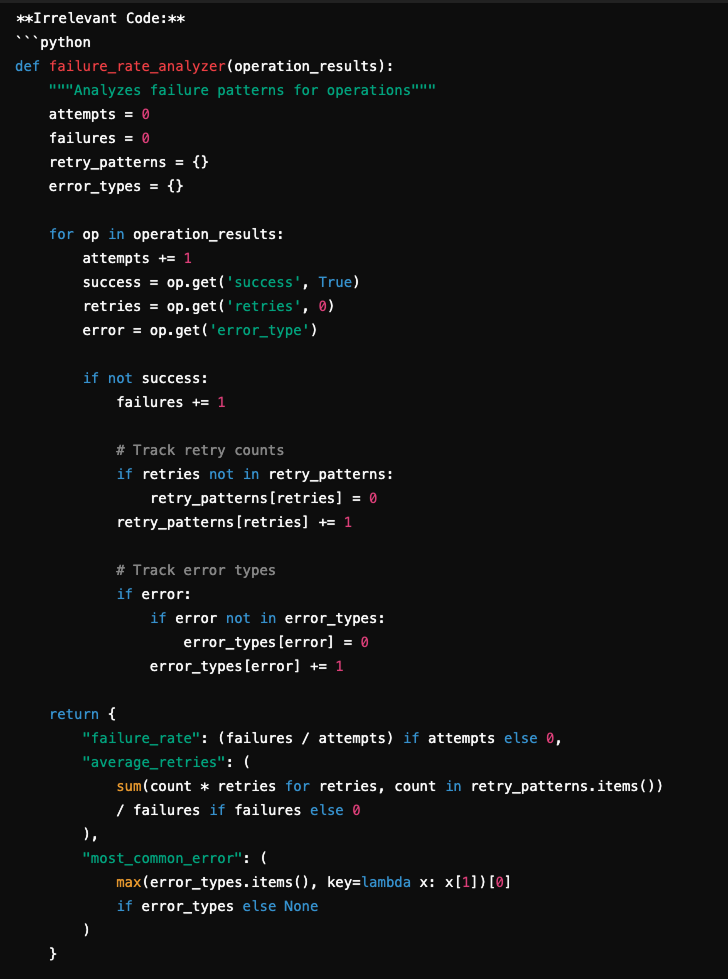
Although this snippet correctly linked to ‘failures’ and ‘operations’, it will never implement it to ensure operational failures – the fact is reported. The models of the content of the shared keywords (“failure,” surgery “), and Miss NanCediced but crucial Code functions. If it’s unable to recognize things like failing to make it difficult to get rid of failures (analyzing failures failure.
At first, we told the semantic mismatch by creating natural language descriptions for our codes snippets using llmms using these descriptions in addition to the raw code. This method of dual-index Our acquisition system is allowed to better align the native language questions related code snippetsessentially developing search accuracy. However, these descriptions are produced in the overhead overhead, increases indexing complex, and is added latency.
By using a code embedded model, we can skip the measure of the General Did not sacrifice performance. It simplifies the system and reduce costs.
Synticetic Data Dake
We refer to two embedded models, based on qwen2-1.5b and qwen2-7b indeed, but experienced an important challenge in a sense of training data needed to claim the model language and natural language. Synthetic Data Helped here by creating natural language descriptions for the existing code to fill the gaps.
For Qodo-Embed-1, we have built a pipeline automatically scraping the open-source code from Gushb, and then inject data with data with data with synthetic saints.
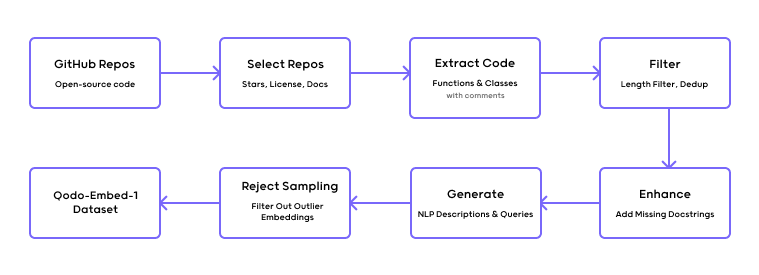
Docstring generation
For the tasks that are deficient in documentation, we have created many synthetic stewards, from the formatting documentation to engrave the natural language summaries.
The prompting we use for creating synthetic docstrings:
Input: a function of python or method without restriction.
Output: A brief and doc-string info depicting the purpose of moving, in-puttion, and outputs.
Prompt: Create a detailed docstring for the following function. Include:
-
- A clear description of what function is done
- All parameters of their types and descriptions
- Return News (s) with Type and Description
- Any exception to be raised
Here is the function: (Input function here) Docstring format using Poogle-style style. Be specific about types and make sure documentation is clear and comprehensive. Just give docstring and no more
Generation of Query Query
In order to make the tasks of search code, we need to improve semantic alignment between code and questions and additional docstrings with additional context. We use a prompt to create natural language questions equal to the given code:
Input: a code snippet enforcing a specified function.
Output: An inherent language method can be used by a developer to find this function.
Prompt:
You are a question generator. Your role is to produce a short and short question of searching the natural language that developers can find similar code solutions. The analysis snippet code will be given below.
Output rules:
– Create search query only.
– No explanations or additional text.
– Length: 10-30 words.
– Use common programming terminology.
– Clearly get the Core function code.
Good Examples:
(Enter the clear and brief examples of good searching questions here.)
Bad examples:
(Enter the examples of poor quality questions here.)
Input function:
(Enter the Function signature or definition here)
Function docstring:
(Enter the availability or device docstring here)
Code Snippet:
(Enter the full code snippet here)
Benchmarking Qodo-Emzed-1
COIR Benchmark (Code information has already measured a model’s ability to create different functions of capture code in different programs.
The QODO embed-1-1.5b achieves an outstanding balance between effectiveness and performance, repair the most greater models. In the coir benchmark it achieved 68.53, greater competitors such as open-up opening models like super-embedding-2_r (67.4.41). Meanwhile, the QODO embed-1-7b increases the bar by scoring 71.5, also outsform the same size models. This efficacy allows teams to effectively find many cenerebases that do not get high computational or practical depreculments.
Now, let’s look at our first question:
Question: Make operations more reliable when they will fail sometimes
If our modeling model is used in the code, qodo embed-1-7b, the resulting result is joining the object of question. Instead of analyzing only past failures, the returned snippet enforces an active modification mechanism to enhance reliably:
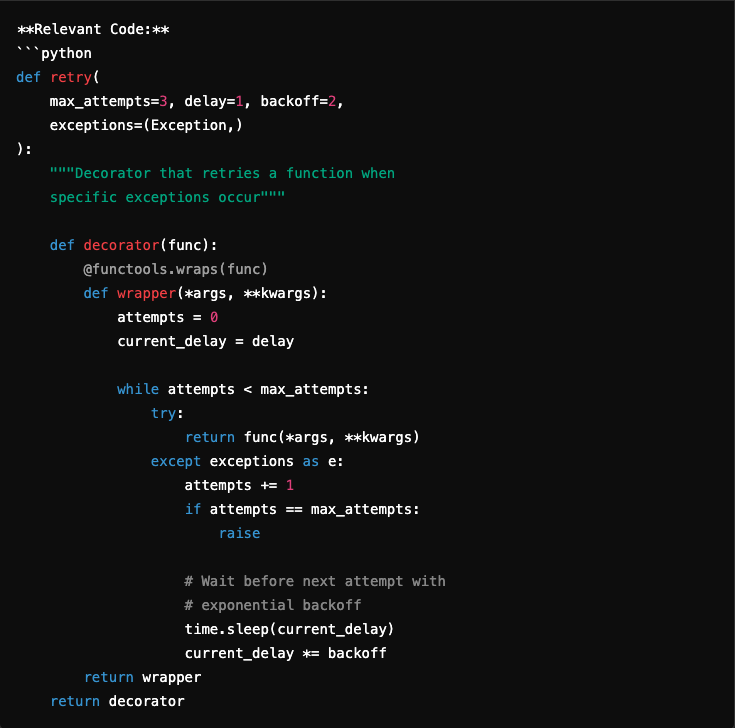
This snippet is a better because it is directly addressed to the user’s intention by active handling of operational failures by a simple retrying mechanism. Instead of relying on keywords similar to “failure” or “operations,” the embedding model meaning in semantic semantic semantic semantic needs.
Why Model size items
While large models are powerful, their size can limit access and deploy. QODO Embed-1 is designed to provide top-tier performance with fewer parameters, which are more efficient and effective costs for those who are approved. Small models are faster to deploy, require less computation resources, and easier tone for specific use cases.
Finally
Finally, the code-embedding models served the machine behind the rag systems, especially for coding agents. A more eleved code Embedding Model makes Qodo establish better tools for getting and analysis code.
The QODE-Embed-1 model is available to face face. Dig-erded-1-1.5b open scales under the open ++ – m licensce, while Dig-erded-1-7b commercial available.
https://www.qodo.ai/wp-content/uploads/2025/02/Blog-Qodo-Embedding-model.png
2025-03-03 17:24:00



