
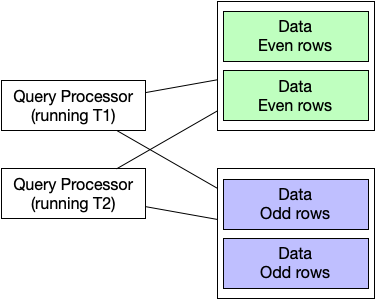
Now, we will build a small database system. For availability, latency, and distress, we divide our data to multiple shards, there are many replicas of each shard. As a block diagram, it looks like this:
Next, borrowing is severely from anchoriteWe will keep some SQL.
begin; -- T0
create table test (id int primary key, value int); -- T0
insert into test (id, value) values (1, 10), (2, 20), (3, 30); -- T0
commit; -- T0
To be very good. We entered three rows in our database. Next, we will run two equal transactions (from two different connections, call them T1 and T2), like so:
begin; -- T2
begin; -- T1
select * from test where id = 1; -- T1. A: We want this to show 1 => 10.
update test set value = value + 2; -- T2
select * from test where id = 2; -- T1. B: We want this to show 2 => 20.
commit; -- T2
select * from test where id = 3; -- T1. C: We want this to show 3 => 30.
commit; -- T1
There is only one valid serializable1 Order these transactions: On line A,, T1 saw the world before T2 achievements, and therefore need to see the sameT2 World until it’s done. Therefore T1 should take place before T2 in serial order.
How do we implement this requirement to our distributed architecture?
We can use locking: T1 takes a shared lock on id = 1 on A,, T2 blocks of this when trying to get an exclusive lock to update the array, and T1 can be completed. There are two practical problems with this procedure. First, we have prevented a writer to a reader, which reduces excitement and by output. Second, specific to our distributed architecture, T1 should take the lock in a place where T2 should find it. With many replicas, which place is not clear. To be resolved by selecting a primary replica, implementing a lock manager, or by locking all replicas2. In all three cases, reading scalability is lost and need to read coordination.
ATTEND David P. Reed’s 1979 job in versions. Replacement T2 make the desired changes in place, it makes a new instinct in rows, only visible in transactions to begin after T2 conditions. T1that began earlier, didn’t see these new versions. Should be provided in storage layer T1 a way to ask for reading this as a specified version, which is done by storing multiple copies of data.
Its impact on our database coordination is important: T2 never need to block T1. In fact, T2 No need to know that T1 It’s really. T1 may be in the corner, that making readings happily against a million data replicas, and T2 never more wise. It helps scalability (Preventing coordination is key to scalability), but also helps pass (writers who do not need to wait for readers, readers should not wait for readers, and do not wait for readers who cannot slow down readers). Since early 1980s, multi-chemection is a main method of enforcing database systems, but it is the role of avoiding the distribution coordination of systems is not well known.
The most powerful version is because it allows the system with an additional piece of information (when does this data do?) About INFORMATION that does not have to know from coordination patterns. As Reed wrote in 1979:
Since (versions) items used in programs, they provide a tool for programming that allows clearly recognizing steady state within the program. In contrast, traditional synchronization mechanisms, such as semaphores, locking, monitoring, addect, and claiming states representing states repented by states state of relationships with measures of programs.
Versions are the difference between awareness of steady states and should be hoarse HOURSEOUS QUESTIONS! That’s a strong idea.
Choosing a version, serving a version
Above, I talk about that T1 Requests to read it as-of a particular version. It produces two questions: How to choose the version, and how to track the storage engine in all versions.
How to choose a version depends on the many assets you want. Serializability, in a common sense, allow read transactions only to select any version (including The beginning of timereturn to unpaid results for all reading). This sense is foolish. Let’s get back to SQL to think about the results we want:
begin; -- T2
begin; -- T1
select * from test where id = 1; -- T1. A: We want this to show 1 => 10.
update test set value = value + 2; -- T2
commit; -- T2
begin; -- T3
select * from test where id = 3; -- T3. D: We want this to show 3 => 32.
commit; -- T3
select * from test where id = 3; -- T1. C: We want this to show 3 => 30.
commit; -- T1
Here, lines A and C did the same thing as our first snippet, but we introduced a third transaction T3. In line DWe show what most programmers expect: a new transaction starting after T2 Conditions see the consequences of T2The letter wrote. This purpose, informal, called read-after writing consistency (generally considered a kind of Strongly consistent)3. There are many ways to achieve this goal. One is to have a Authority Version Those hands in transaction numbers version of a tight order – but it also identifies the exact coordination we try to avoid!
on Aurora DSQLWe chose this time using a physical clock (EC2’s accurate microsecond Time-Sync Service). This allows us to avoid all coordination between readers, including readings within reading reading transactions T2s UPDATE should be a read-new-writing to find new value for each row).
The basic idea of using the physical time this way begins in the late 1970s, although most people recognize difficulty in synchronization problem. Pretty fun, Reed said:
Synchronization of system clocks whenever they come by using the operator’s watch usually gets the timely time within a few minutes
Before notice to note that light clocks allow the system to make better. The 1970s approval as adequate physical synchronization of the body cannot – now readily available in the cloud.
Track all versions!
The next question is how to track all versions. It’s a deep self-question, with tons of interesting trade-offs and different ways. I don’t follow those who are here, but instead of getting a different tack. Let’s break up T1 From our last example:
begin; -- T1
select * from test where id = 1; -- T1. A: We want this to show 1 => 10.
select * from test where id = 3; -- T1. C: We want this to show 3 => 30.
commit; -- T1
that we can rewrite As:
begin; -- T1 (gets timestamp 't1_v')
select * from test where id = 1 and version <= t1_v order by version desc limit 1;
select * from test where id = 3 and version <= t1_v order by version desc limit 1;
commit; -- T1
Similarly, T2 rewrite as an as well as a INSERT to a new version number. I don’t know any database system implemented this way, but it’s a great description that brings us to two invarients we need to keep around the versions:
- Must have at least one version of each with a line, and
- The versions used by running transactions should be kept.
That is, we need to press the last version (or lost the whole), and we must continue t1_v at least until T1 have been completed. The former property is a local deer, which can be executed in each copy without coordination. The last one is a distribution to the USA, which brings us back to our coordination theme.
Once again, we can clearly solve this coordination problem: Register each running transaction on a list, tracking timestamp in the water-market. That is possible to build (and even scaling real), but it is good to avoid that coordination. At Aurora DSQL we avoid coordination in a simple way: transactions are limited to time (five minutes at the current release of preview. It turns into invariant 2 to a local property too, once again avoiding coordination4.
Finally
With distributed database systems, versioning and physical clocks allow coordination to avoid almost all cases of reading. This is a more powerful tool, because avoiding coordination improves development and excavation, reducing latency and cost, and enables the design of systems.
Footnotes
- If we want to translate it to SQL’s solitude level, see
1=>10onAand3=>32onCwill be allowedREAD COMMITTEDBut not allowed toREPEATABLE READor higher degree of solitude (enraged snapshot-snapshot-unitedREPEATABLE READlevel). Sight1=>10onAand2=>22onBjust let itREAD UNCOMMITTED. lineBshows that our system is restricted Dirty ReadsandCshows that it can hold Read the skew. - Bernstein and Travel to Bernman and Goodman’s paper Controvers control of Database Systems Checked these methods in Section 3.
- If you want to fix it, Jseen’s concentrations page a great place to start.
- It works because of OLTP focus on DSQL, but not at an orasa or reporting the system where higher transactions are expected. To those systems, a different approach is required, coming to a whole challenges.
2025-02-06 06:10:00


